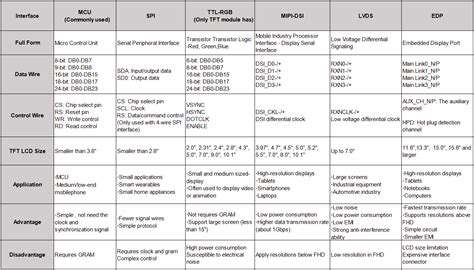
Data Acquisition and Preprocessing
Gathering raw sensor inputs marks merely the initial phase. High-performing machine learning systems demand painstakingly curated information. This preparatory stage encompasses data cleansing, conversion, and potential enhancement to guarantee compatibility with model training protocols. Tasks may involve addressing gaps in data, eliminating anomalous readings, transforming formats for algorithm compatibility, and implementing normalization techniques to prevent feature dominance. Proper preprocessing dramatically influences model precision and dependability, establishing it as a pivotal stage within the operational sequence.
Information verification proves indispensable during this phase. Validating that datasets accurately represent intended applications and remain devoid of systemic flaws is paramount. Methodologies like dataset segmentation (e.g., training, validation, and testing partitions) facilitate performance evaluation against novel data, preventing over-specialization while delivering authentic assessments of generalization capacity. These verification procedures constitute essential components for constructing resilient machine learning architectures for sensor analytics.
Feature Engineering and Selection
Deriving actionable intelligence from unprocessed sensor outputs necessitates meticulous feature development. This process generates novel characteristics through computational transformations of existing parameters. For instance, accelerometer measurements might yield derived metrics like mean acceleration values, peak acceleration thresholds, or temporal variation patterns - collectively providing enhanced descriptive power regarding underlying phenomena. Feature engineering essentially converts raw measurements into formats better suited for computational modeling frameworks.
Moreover, discerning pertinent features proves vital for operational efficiency and predictive accuracy. Feature relevance varies significantly, with certain attributes contributing minimally to model performance. Analytical approaches including correlation assessments, importance weighting from trained models, and dimensional compression techniques (e.g., Principal Component Analysis) assist in isolating the most informative variables, thereby reducing interference while enhancing processing velocity and precision. Strategic feature development and selection represent fundamental prerequisites for creating transparent, high-performance machine learning implementations.
Application-specific considerations and sensor characteristics demand careful attention. Varied sensor technologies, measurement standards, and sampling frequencies require customized feature development approaches. Optimal feature identification typically involves experimental iteration and progressive refinement cycles.
By concentrating on the most relevant and predictive features, computational overhead diminishes while ensuring model focus remains aligned with critical data aspects - ultimately yielding superior forecasting capabilities.
This phase remains indispensable for constructing models that effectively harness sensor data to achieve targeted objectives.
Real-Time Decision Making: Steering, Accelerating, and Braking
Steering Decisions with Data
Continuous decision formulation within machine learning contexts depends fundamentally on instantaneous data interpretation and responsive action adjustment. This requires uninterrupted information flow processing, ranging from sensor outputs to environmental fluctuations, enabling systems to adapt dynamically to evolving conditions. Effective steering mechanisms rely on algorithms capable of deciphering these data streams and converting them into executable commands, guaranteeing peak performance and reactivity in time-sensitive applications. Such architectures must demonstrate sufficient robustness to accommodate unpredictable variations while preserving accuracy during high-pressure scenarios.
Steering in this paradigm incorporates not only immediate response capabilities but also forward-looking anticipation. Predictive frameworks, educated through historical patterns, empower systems to forecast potential challenges or advantages. This preemptive methodology facilitates early intervention, reducing the consequences of unexpected developments while optimizing operational efficiency.
Accelerating Decision Speed
Velocity constitutes a critical factor in instantaneous decision processes. Machine learning architectures must analyze information with exceptional speed to ensure prompt reactions. Algorithm optimization, specialized processing hardware utilization, and parallel computation strategies become essential for achieving necessary throughput rates. This acceleration transcends mere latency reduction, encompassing complete decision cycle minimization to guarantee system responsiveness aligns with application requirements.
Furthermore, systemic infrastructure significantly influences decision velocity. Optimized data channels, efficient storage solutions, and strategically implemented caching systems collectively contribute to reducing overall processing duration. These architectural elements, combined with algorithmic improvements, prove indispensable for creating frameworks capable of meeting real-time operational demands.
Braking Inefficient Processes
Within the fluid context of instantaneous decision-making, inefficiency detection and mitigation become crucial. Machine learning models, despite their sophistication, may produce suboptimal outputs without proper oversight. Continuous performance monitoring through feedback mechanisms and quantitative metrics enables identification of potential constraints, erroneous premises, or areas requiring procedural modifications. This facilitates immediate corrective action and prevents error propagation.
Through persistent system evaluation, issues like resource depletion, data anomalies, or algorithmic drift become detectable and addressable. This proactive approach to process optimization ensures sustained accuracy and responsiveness, preventing potential system failures while maximizing operational effectiveness.
The Role of Machine Learning in Real-Time Decision Making
Computational learning algorithms form the core of instantaneous decision architectures. These models, trained on extensive historical datasets, identify underlying patterns and correlations, enabling real-time forecasting and recommendations. From financial fraud identification to automated trading systems, machine learning drives numerous applications requiring rapid, precise decision capacities.
Model adaptability proves particularly valuable in dynamic environments. As novel data emerges, frameworks can undergo retraining and updates to incorporate evolving trends and patterns. This ensures decision relevance and accuracy persists despite changing circumstances.
Data Quality and Real-Time Decision Making
Instantaneous decision accuracy maintains direct correlation with training data integrity. Flawed, incomplete, or inconsistent datasets may generate unreliable predictions and actions. Comprehensive data acquisition protocols, validation procedures, and cleansing methodologies prove essential for preserving information quality and ensuring dependable outputs.
Preprocessing techniques, including missing value imputation, outlier removal, and feature transformation, play critical roles in preparing information for effective analysis. These steps guarantee machine learning models train on reliable, standardized datasets, producing more accurate and trustworthy real-time decisions.
The Future of Real-Time Decision Making
The instantaneous decision-making field undergoes constant advancement, propelled by machine learning innovations and computational power growth. Emerging technology integration, including edge computing and distributed cloud platforms, will further enhance system speed and efficiency. These developments will enable deployment of more sophisticated algorithms and processing of larger datasets, yielding increasingly precise and responsive systems.
Future applications may encompass autonomous transportation networks, customized medical interventions, and dynamic resource management systems. As these technologies mature, we can anticipate expanding roles for real-time decision architectures in shaping technological and social landscapes.
Continuous Learning and Adaptation: Improving Autonomous Driving Capabilities
Continuous Improvement Through Data
Self-driving systems, distinct from human operators, depend extensively on diverse data streams to refine environmental comprehension. This ongoing educational process incorporates information from multiple sources including sensor outputs, positional data, and actual driving conditions. Through rigorous analysis, algorithms discern patterns, anticipate potential dangers, and modify behaviors accordingly, resulting in progressive capability enhancement. This cyclical learning mechanism forms the cornerstone for long-term autonomous vehicle development and dependability.
Dataset quality and volume represent critical factors. Comprehensive collections spanning varied meteorological conditions, roadway types, traffic configurations, and challenging scenarios prove essential for developing holistic environmental understanding. This empirical methodology enables systems to adjust to unforeseen events and make informed instantaneous decisions, ultimately improving safety and operational efficiency.
Adaptive Algorithms for Dynamic Environments
Autonomous navigation systems must demonstrate environmental adaptability. This necessitates advanced algorithms capable of synthesizing information from multiple sensors (e.g., optical, radio detection, light-based ranging) to create comprehensive situational awareness. These algorithms undergo continuous refinement to enhance dynamic event recognition and response capabilities, including abrupt lane deviations, pedestrian crossings, or unexpected obstructions.
Developing self-correcting algorithms that learn from errors and adjust to new conditions proves essential. Deep learning techniques particularly enable autonomous vehicles to recognize complex patterns and generate accurate real-time predictions. This adaptive capacity remains fundamental for ensuring system safety and reliability across diverse driving situations.
Real-World Testing and Validation
The continuous learning paradigm for autonomous systems relies heavily on practical evaluation. Controlled environment testing (e.g., proving grounds) serves critical roles in initial algorithm development and calibration. However, authentic validation emerges from extensive real-world operation across varied conditions, including public roads, inclement weather, and complex traffic scenarios.
Data collection during actual deployments proves invaluable. These operations expose systems to circumstances difficult to simulate, facilitating identification of improvement areas and ongoing algorithm refinement. Insights gained from practical testing contribute significantly to enhancing system safety, performance, and dependability.
Maintaining Ethical Considerations
As autonomous systems grow increasingly sophisticated, ethical principles must remain central to the learning and adaptation process. Algorithms require programming that prioritizes safety and complies with established ethical standards, particularly in ambiguous circumstances. This involves thorough risk assessment and decision protocol design reflecting societal values.
Developing systems capable of consistent ethical judgment amid uncertainty, while simultaneously learning from these experiences, presents substantial challenges. This persistent ethical focus proves essential for fostering public confidence and acceptance of autonomous vehicle technology.