The Rise of Connected Car Technology
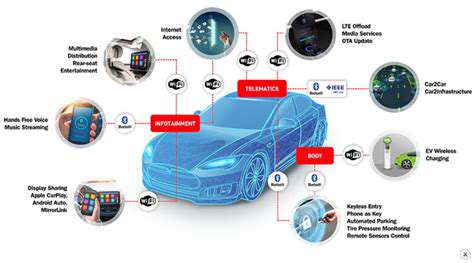
The Foundation of Connectivity
The evolution of connected car technology hinges on the seamless integration of various electronic systems. This integration allows for real-time data exchange between the vehicle's onboard computers and external networks. This foundational connectivity paves the way for a plethora of innovative features, transforming the driving experience and enhancing safety. The core components, such as embedded telematics and communication modules, are critical to establishing this network, enabling features like remote diagnostics and over-the-air updates.
Enhanced Safety Features
Connected car technology plays a pivotal role in enhancing safety by providing real-time accident detection and response systems. These systems can automatically alert emergency services in the event of an accident, significantly improving response times and potentially saving lives. Furthermore, advanced driver-assistance systems (ADAS) leverage connected data to provide proactive warnings about potential hazards, such as lane departures or approaching vehicles, increasing safety on the road.
Improved Convenience and User Experience
Connected car technology drastically improves the overall user experience. Features like remote vehicle control, allowing you to lock/unlock your car or start the engine remotely, add significant convenience to daily life. The integration of entertainment and navigation systems, often controlled through intuitive touchscreens or voice commands, further elevates the driving experience.
Data Collection and Analysis
The vast amount of data generated by connected cars offers valuable insights into driving patterns, vehicle performance, and even traffic flow. This data allows for the development of more efficient traffic management systems, personalized maintenance schedules for vehicles, and ultimately, more sustainable transportation solutions. Analyzing this data helps manufacturers optimize vehicle design and improve overall performance.
Over-the-Air Updates and Maintenance
Connected cars enable over-the-air (OTA) software updates, allowing for the continuous improvement and enhancement of vehicle features and performance. This capability eliminates the need for costly and time-consuming in-person visits to the service center for crucial updates and bug fixes. This remote maintenance and software update capability is a significant advancement that leads to improved reliability and safety.
Security Concerns and Future Implications
While the benefits of connected car technology are substantial, security remains a significant concern. Hackers could potentially exploit vulnerabilities in the connected systems to gain control of the vehicle, posing a serious threat to both driver and passenger safety. Robust security measures are crucial to mitigating these risks, and this remains an area of ongoing technological advancement. The future of connected car technology promises further integration with other technologies, such as autonomous driving systems and smart cities, creating an increasingly interconnected and intelligent transportation network.
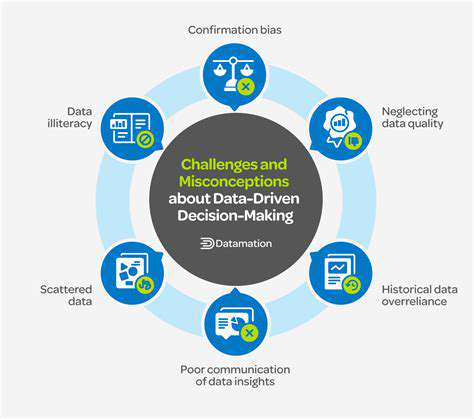
Identifying Potential Issues with Machine Learning
Data Quality and Bias
Ensuring the quality of the data used in machine learning models is paramount. Inaccurate, incomplete, or inconsistent data can lead to flawed predictions and unreliable insights. Furthermore, existing biases within the data itself can perpetuate and even amplify societal prejudices, leading to unfair or discriminatory outcomes. Identifying and mitigating these biases is crucial for responsible and ethical machine learning development, especially in sensitive applications like loan applications or criminal risk assessments.
Careful data cleaning and preprocessing steps are essential to address these issues. Techniques like outlier detection and imputation can help to manage incomplete or erroneous data points. Equally important is the need to critically examine the data for potential biases. This involves understanding the historical context and potential sources of bias, and taking proactive measures to minimize their impact on model performance.
Model Selection and Complexity
Choosing the right machine learning model is critical for achieving accurate and reliable predictions. Overly complex models can lead to overfitting, where the model performs exceptionally well on the training data but poorly on new, unseen data. Conversely, overly simplistic models may fail to capture the nuances of the underlying patterns, resulting in inaccurate predictions.
Carefully evaluating the trade-offs between model complexity and performance is essential. Techniques like cross-validation can help to assess the model's generalization ability and prevent overfitting. Considering the specific nature of the problem and the available data is equally important when selecting the most appropriate model. A model designed for image recognition will perform poorly on a problem involving time-series data, for example.
Feature Engineering and Selection
The features used to train a machine learning model significantly impact its predictive power. Appropriate feature engineering involves transforming and combining existing variables to create new, informative features. This can improve model performance and reduce the risk of overfitting.
Feature selection is another crucial aspect. Identifying the most relevant features from a large set can improve model efficiency and interpretability. Methods like recursive feature elimination or correlation analysis can help to determine which features contribute the most to the model's predictive power, while removing redundant or irrelevant ones.
Evaluation Metrics and Thresholds
Defining appropriate evaluation metrics is vital for assessing the performance of a machine learning model. Metrics like accuracy, precision, recall, and F1-score provide different perspectives on the model's effectiveness. The choice of metric depends on the specific application and the relative importance of different types of errors. For example, in a medical diagnosis, a high false negative rate might be more problematic than a high false positive rate.
Setting appropriate thresholds for predictions is also essential. A model might predict a high probability of a certain event, but the threshold used to classify that event as positive or negative can significantly impact the results. Adjusting these thresholds can balance the trade-off between accuracy and the risk of false positives or negatives, depending on the specific context.
Deployment and Maintenance
Deploying a machine learning model into a production environment requires careful consideration. Ensuring that the model continues to perform accurately over time is crucial. Changes in the data distribution or the underlying processes might cause the model to degrade over time.
Interpretability and Explainability
Understanding how a machine learning model arrives at its predictions is crucial, especially in sensitive applications. Black box models, where the decision-making process is opaque, can be difficult to trust and may raise concerns about fairness and accountability. Techniques to improve interpretability, such as feature importance analysis or rule extraction, can increase trust and transparency.
Overfitting and Generalization
Overfitting occurs when a model learns the training data too well, including its noise and outliers. This results in poor generalization, meaning the model doesn't perform well on new, unseen data. Techniques like regularization, cross-validation, and early stopping can help to mitigate overfitting and improve the model's ability to generalize to new data points. Understanding the limitations of the model and its potential for error is critical for responsible deployment.